
Differentiable Algorithm Network (DAN) aims to combine the strengths of modal-based algorithmic reasoning and model-free deep learning for robust robot decision-making under uncertainty. Key to our approach is a unified neural network policy representation, encoding both a learned system model and an algorithm that solves the model. The network is fully differentiable and can be trained end-to-end, circumventing the difficulties of direct model learning in a partially observable setting. In contrast with conventional deep neural networks, our network representation imposes the model and algorithmic priors on the neural network architecture for improved generalization of the learned policy.
QMDP-Net
P. Karkus, D. Hsu, and W. S. Lee. QMDP-Net: Deep Learning for Planning Under Partial Observability. In Advances in Neural Information Processing Systems, NeurIPS, 2017.
PDF | code
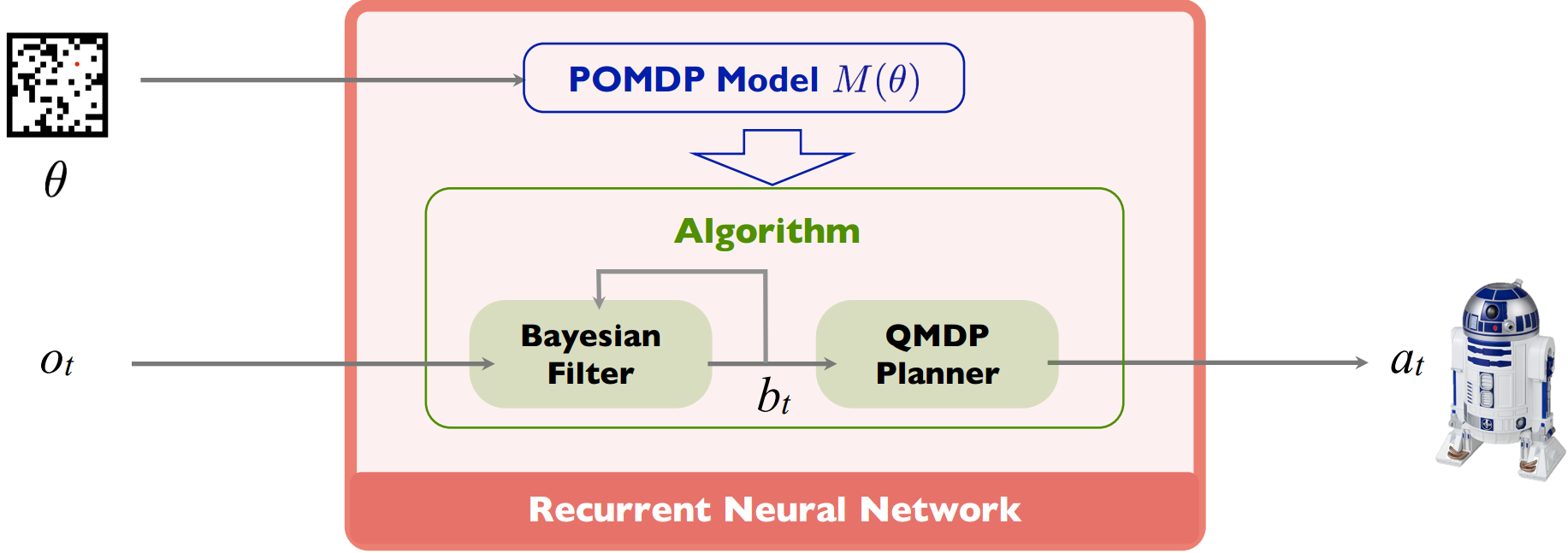 QMDP-net employs algorithm priors on a neural network for planning under partial observability. The network encodes a learned POMDP model together with QMDP, a simple, approximate POMDP planner, thus embedding the solution structure of planning in a network learning architecture. We train a QMDP-net on different tasks so that it can generalize to new ones in the parameterized task set, and “transfer” to other similar tasks beyond the set. Interestingly, while QMDP-net encodes the QMDP algorithm, it sometimes outperforms the QMDP algorithm in the experiments, as a result of end-to-end learning.
QMDP-net employs algorithm priors on a neural network for planning under partial observability. The network encodes a learned POMDP model together with QMDP, a simple, approximate POMDP planner, thus embedding the solution structure of planning in a network learning architecture. We train a QMDP-net on different tasks so that it can generalize to new ones in the parameterized task set, and “transfer” to other similar tasks beyond the set. Interestingly, while QMDP-net encodes the QMDP algorithm, it sometimes outperforms the QMDP algorithm in the experiments, as a result of end-to-end learning.
Navigation Network (Nav-Net)
P. Karkus, D. Hsu, and W. S. Lee. Integrating Algorithmic Planning and Deep Learning for Partially Observable Navigation. In MLPC Workshop, International Conference on Robotics and Automation, 2018.
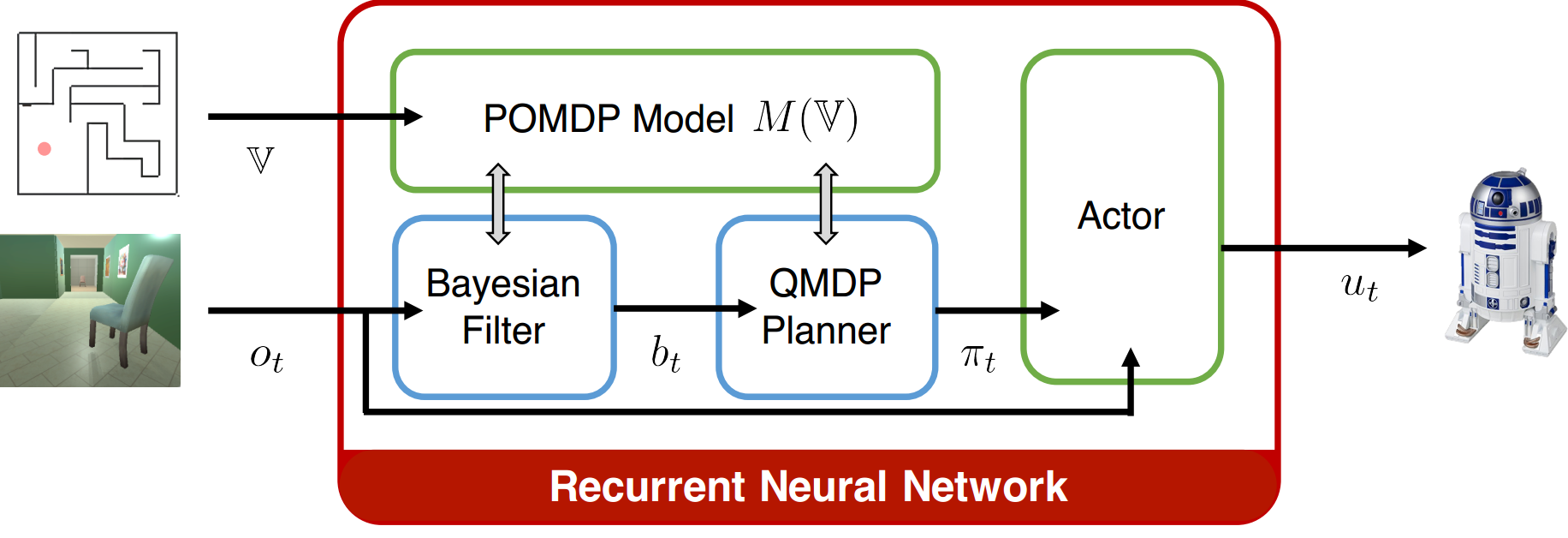 This work extends the QMDP-net, and encodes all components of a larger robotic system in a single neural network: state estimation, planning, and control. We apply the idea to a challenging partially observable navigation task: a robot must navigate to a goal in a previously unseen 3-D environment without knowing its initial location, and instead relying on a 2-D floor map and visual observations from an onboard camera.
This work extends the QMDP-net, and encodes all components of a larger robotic system in a single neural network: state estimation, planning, and control. We apply the idea to a challenging partially observable navigation task: a robot must navigate to a goal in a previously unseen 3-D environment without knowing its initial location, and instead relying on a 2-D floor map and visual observations from an onboard camera.
Particle Filter Network (PF-Net)
P. Karkus, D. Hsu, and W. S. Lee. Particle Filter Networks with Application to Visual Localization. In Conference on Robot Learning, CoRL, 2018.
PDF | code
 |
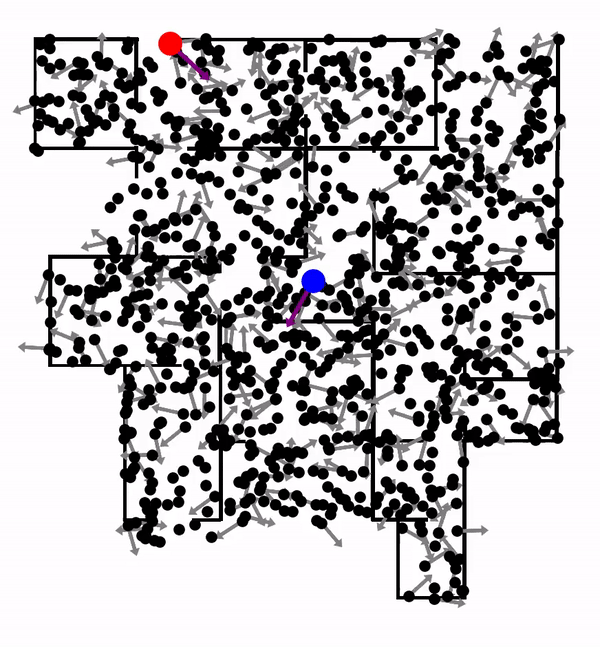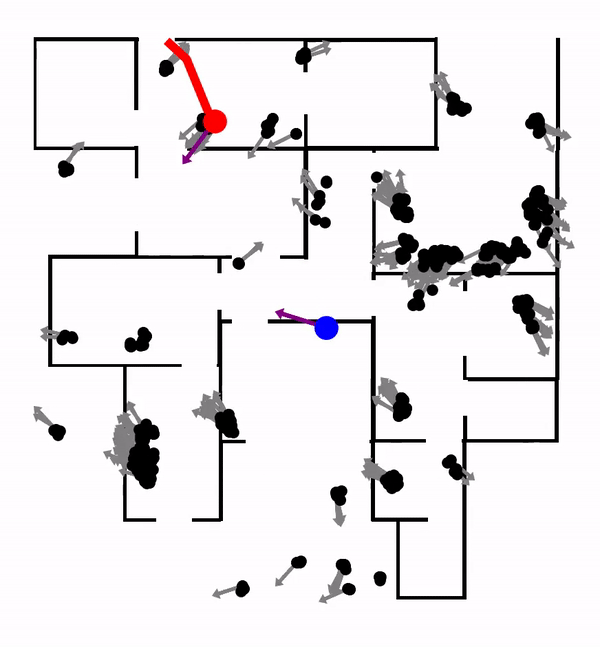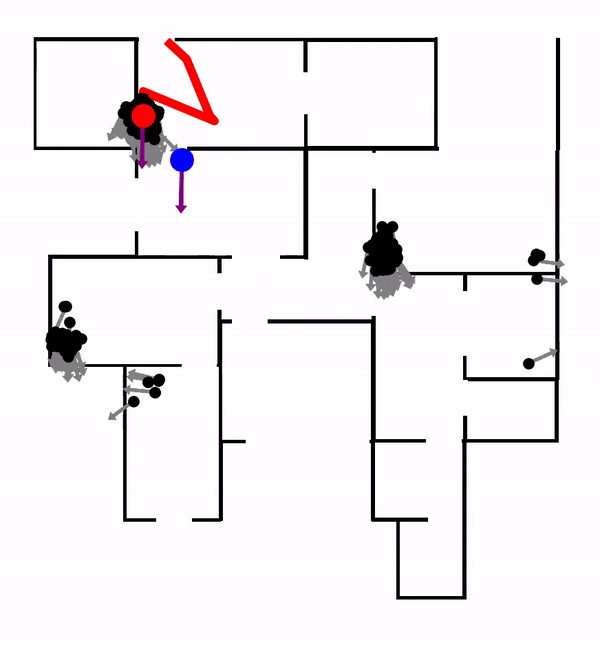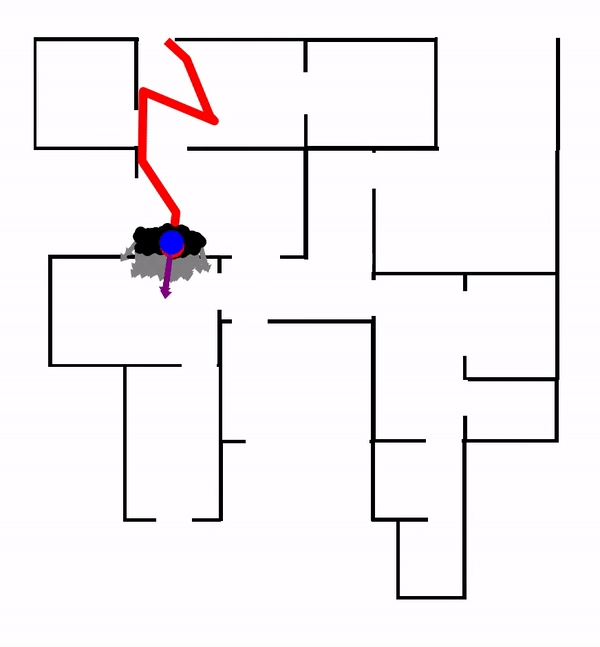 |
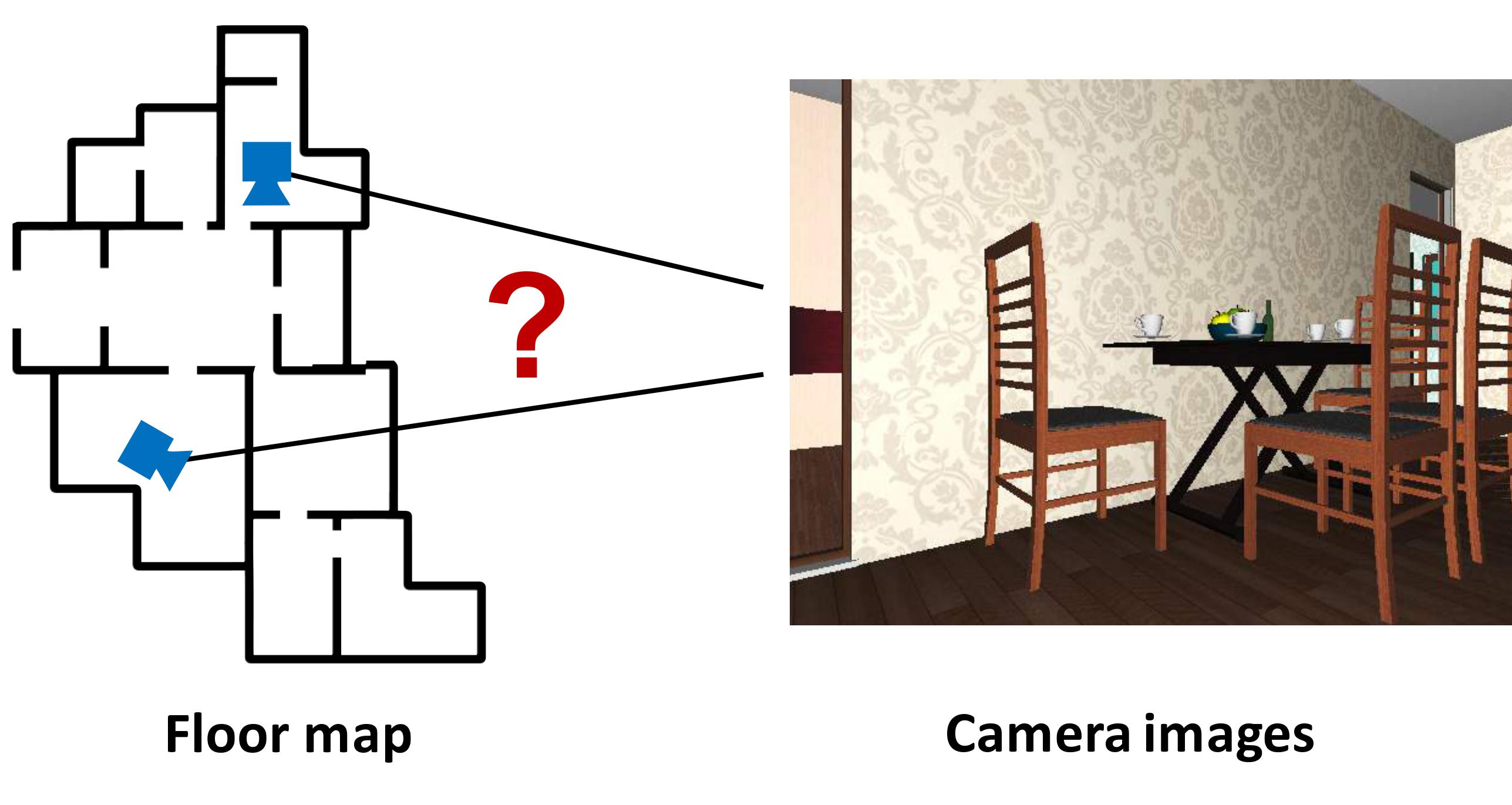
In this work, we encode the Particle Filter algorithm in a differentiable neural network. PF-net enables end-to-end model learning, which trains the model in the context of a specific algorithm, resulting in improved performance, compared with conventional model-learning methods. We apply PF-net to visual robot localization. The robot must localize in rich 3-D environments, using only a schematic 2-D floor map. PF-net learns effective models that generalize to new, unseen environments. It can also incorporate semantic labels on the floor map.
Read more on PF-nets combined with state representation learning for sequence prediction and RL here; and map respresentation learning here.
Differentiable Algorithm Network (DAN)
P. Karkus, X. Ma, D. Hsu, L. P. Kaelbling, W. S. Lee, and T. Lozano-Pérez. Differentiable Algorithm Networks for Composable Robot Learning. In Robotics: Science and Systems, RSS, 2019. Nominated for the Best Student Paper Award and the Best Systems Paper Award.
 DANs compose modules of differentiable robot algorithms and associated models into a single neural network that is trained end-to-end from data. From a model-free policy learning perspective the algorithms in DAN act as structured prior. From a model-based RL perspective, instead of training models to match the underlying system dynamics, DAN trains models end-to-end to optimize the overall task objective by backpropagating gradients through the algorithms. The benefit of task-oriented learning is that models and algorithms can adapt and compensate for each others’ imperfections. We illustrate the DAN methodology using differentiable modules for visual perception, state filtering, planning, and local control in the context of a partially observably visual navigation task in 3-D environments.
DANs compose modules of differentiable robot algorithms and associated models into a single neural network that is trained end-to-end from data. From a model-free policy learning perspective the algorithms in DAN act as structured prior. From a model-based RL perspective, instead of training models to match the underlying system dynamics, DAN trains models end-to-end to optimize the overall task objective by backpropagating gradients through the algorithms. The benefit of task-oriented learning is that models and algorithms can adapt and compensate for each others’ imperfections. We illustrate the DAN methodology using differentiable modules for visual perception, state filtering, planning, and local control in the context of a partially observably visual navigation task in 3-D environments.