Prediction for Planning refers to the use of predictive models to anticipate future states of a system, enabling more informed decision-making in robotic planning. In domains like autonomous driving, effective planning depends not just on predicting how the world will evolve but also on understanding how the planner’s own actions influence that evolution.
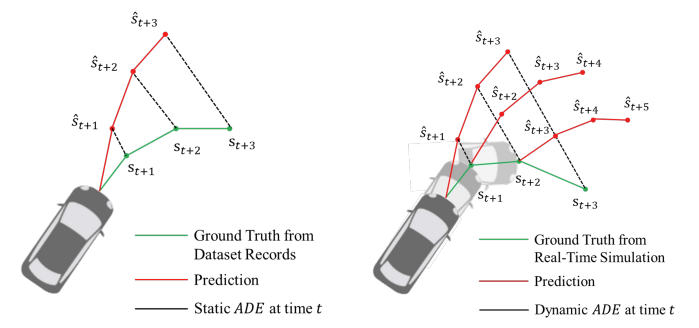
Accurate state prediction is key to effective robot planning, yet conventional models assume fixed environmental dynamics. In interactive settings, robot actions influence environmental responses, creating a dynamics gap that disrupts planning accuracy. This challenge is especially evident in autonomous driving, where trajectory prediction ensures safe and efficient navigation.
Our research tackles this issue through two works: What Truly Matters in Trajectory Prediction for Autonomous Driving? and State Prediction for Planning: Closing the Interactive Dynamics Gap. These works reveal that prediction models, when used in planning, affect agent behavior in ways conventional evaluation methods miss. The first work highlights how the dynamics gap causes discrepancies between predictor accuracy on fixed datasets and real-world performance, emphasizing the need for task-driven evaluation. The second formalizes the compounding effects of prediction and planning errors and introduces a planner-specific learning objective to mitigate this gap, enabling safer, more robust decision-making.
What truly matters:
P. Tran, H. Wu, C. Yu, P. Cai, S. Zheng, and D. Hsu. What truly matters in trajectory prediction for autonomous driving? In Advances in Neural Information Processing Systems, 2023.
PDF
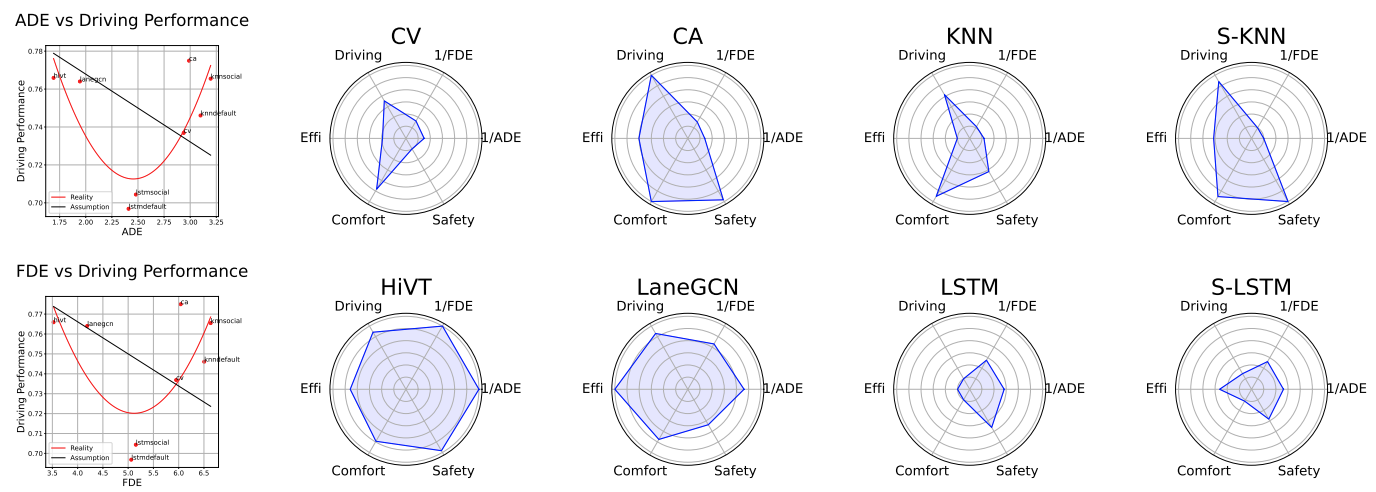
Prediction accuracy vs. driving performance. Our findings show a surprising lack of correlation between conventional prediction metrics (Black Curve) and real-world driving performance (Red Curve). Eight models are evaluated: CV, CA, KNN, S-KNN, HiVT, LaneGCN, LSTM, and S-LSTM.
In the autonomous driving system, trajectory prediction plays a vital role in ensuring safety and facilitating smooth navigation. However, we observe a substantial disparity between the accuracy of predictors on fixed datasets and their driving performance when used in downstream tasks. In this work, we reveal the overlooked significance of the dynamics gap, which plays a dominant role in this disparity. In real-world scenarios, prediction algorithms influence the behavior of autonomous vehicles, which, in turn, alter the behavior of other agents on the road. This interaction results in predictor-specific dynamics that directly impact prediction results. As other agents’ responses are predetermined on datasets, a significant dynamics gap arises between evaluations conducted on fixed datasets and actual driving scenarios. Furthermore, we explore the influence of various factors, beyond prediction accuracy, on the remaining disparity between prediction performance and driving performance. The findings illustrate the significance of predictors’ computational efficiency in real-time tasks, and its trade-off with prediction accuracy in reflecting driving performance. In summary, we demonstrate that an interactive, task-driven evaluation protocol for trajectory prediction is crucial to reflect its efficacy for autonomous driving.
Closing the Interactive Dynamics Gap:
H. Wu, C. Yu, Y. Xu, D. Hsu, and S. Zheng, State Prediction for Planning: Closing the Interactive Dynamics Gap

The prediction model trained with our proposed approach produces driving behavior that is more similar to that of a human expert (Right).
More broadly, effective robot planning requires state prediction models that account for interactive dynamics. Conventional prediction models assume fixed environment dynamics. However, in an interactive setting, robot actions may alter environment dynamics; the future system states no longer follow a fixed distribution, leading to the dynamics gap that violates the i.i.d. assumption of state prediction. In this work, we first analyze how prediction and planning errors interleave over time and establish theoretical bounds on their compounding effect. Next, we introduce a planner-specific objective for learning the prediction model. We validate our approach through both simulated and real-world autonomous driving experiments, demonstrating that our approach significantly improves prediction accuracy, enhances decision robustness, and leads to safer, smoother planning outcomes. One key insight of this work is that the state prediction is planner-specific in interactive robotic systems.