
How can a delivery robot navigate reliably in a new office building, with only a schematic floor map? To tackle this challenge, we introduce Intention-Net (iNet), a two-level hierarchical navigation architecture, which integrates model-based path planning and model-free deep learning.
Intention-Net
W. Gao, D. Hsu, W. Lee, S. Shen, and K. Subramanian. Intention-Net: Integrating planning and deep learning for goal-directed autonomous navigation. In S. Levine and V. V. and K. Goldberg, editors, Conference on Robot Learning, volume 78 of Proc. Machine Learning Research, pages 185–194. 2017.
iNet is a two-level hierarchical architecture for visual navigation. It mimics human navigation in a principled way by integrating high-level planning in a crude global map and low-level neural-network motion control. At the high level, a path planner uses a crude map, e.g., a 2-D floor map, to compute a path from the robot’s current location to the final destination. The planned path provides “intentions” to local motion control. At the low level, a neural-network motion controller is trained end-to-end to provide robust local navigation. Given an intention, it maps images from a single monocular camera directly to robot control. The “intention” provides the communication interface between global path planning and local- neural-network motion control:
- Discretized local move(DLM) intention. We assume that in most cases discretized navigation instructions would be enough for navigation. For example, turning left at the next junction would be enough for human drivers to drive in the real world. We mimic the same procedure by introducing four discretized intentions.
- Local path and environment(LPE) intention. The DLM intention relies on pre-defined parameters. To alleviate the issue, we design a map-based intention encoded all the navigation information from the high-level planner.
Deep rEcurrent Controller for vISual navigatiON (DECISION)
B. Ai, W. Gao, Vinay, and D. Hsu. Deep Visual Navigation under Partial Observability. In IEEE Int. Conf. on Robotics & Automation, 2022.
PDF | code
The iNet navigation controller faces three challenges:
- Visual complexity. Due to the high dimensionality of raw pixels, different scenes could appear dramatically different across environments, which makes traditional model-based approaches brittle.
- Partial observability. The robot may not see blind-spot objects, or is unable to detect features of interest, e.g., the intention of a moving pedestrian.
- Multimodal behaviors. Human navigation behaviors are multimodal in nature, and the behaviors are dependent on both local environments and the high-level navigation objective.
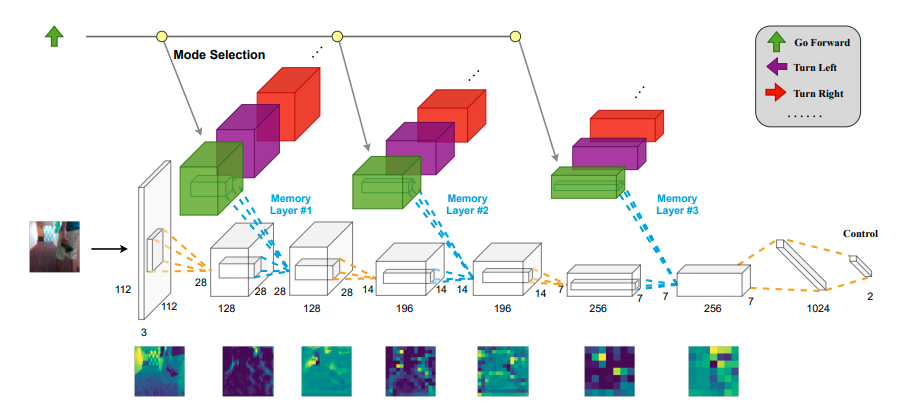
To overcome the challenges, DECISION exploits two ideas in designing the neural network structure:
- Multi-scale temporal modeling. We use spatial memory modules to capture both low-level motions and high-level temporal semantics that are useful to the control. The rich history information can compensate for the partial observations.
- Multimodal actions. We extend the idea of Mixture Density Networks (MDNs) to temporal reasoning. Specifically, we use independent memory modules for different modes to preserve the distinction of modes.
We collected a real-world human demonstration dataset consisting of 410K timesteps and trained the controller end-to-end. Our DECISION controller significantly outperforms CNNs and LSTMs.
DECISION was first deployed on our Boston Dynamics Spot robot in April 2022. The robot has been navigating autonomously for more than 150 km by March, 2022.