This research examines particle-based object manipulation. We start with Particle-based Object Manipulation (PROMPT), designed for the manipulation of unknown rigid objects. PROMPT leverages a particle-based object representation to bridge visual perception and robot control. We expand this particle representation to deformable objects and introduce DaXBench, a differentiable simulation framework to benchmark deformable object manipulation (DOM) techniques. DaxBench enables deeper exploration and systematic comparison of DOM techniques. Finally, we present Differentiable Particles (DiPac), a new DOM algorithm, using the particle presentation. The differentiable particle dynamics aids in the efficient estimation of dynamics parameters and action optimization. Together, these new tools address the challenge of robot manipulation of unknown deformable objects, paving the way for new progress in the field.
Prompt
S. Chen, X. Ma, Y. Lu, D. Hsu. Ab initio particle-based object manipulation. Proceedings of Robotics: Science and Systems, RSS 2021.
PDF | Code
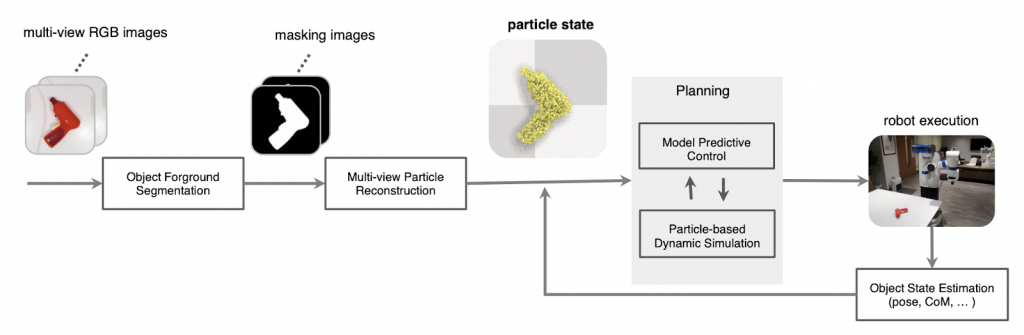
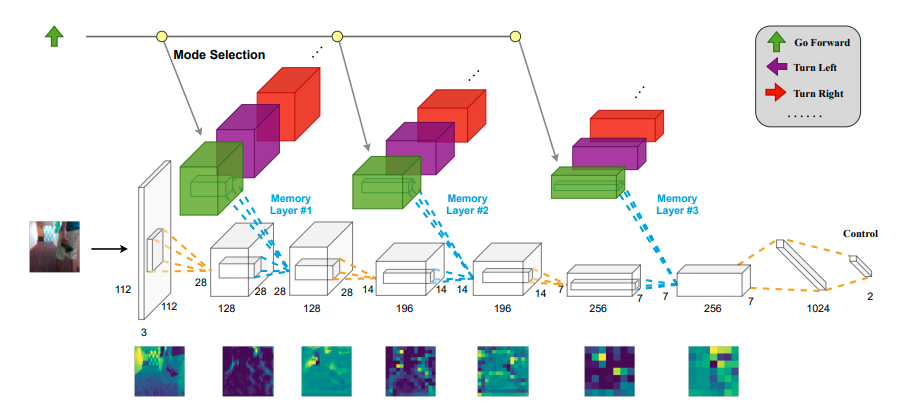
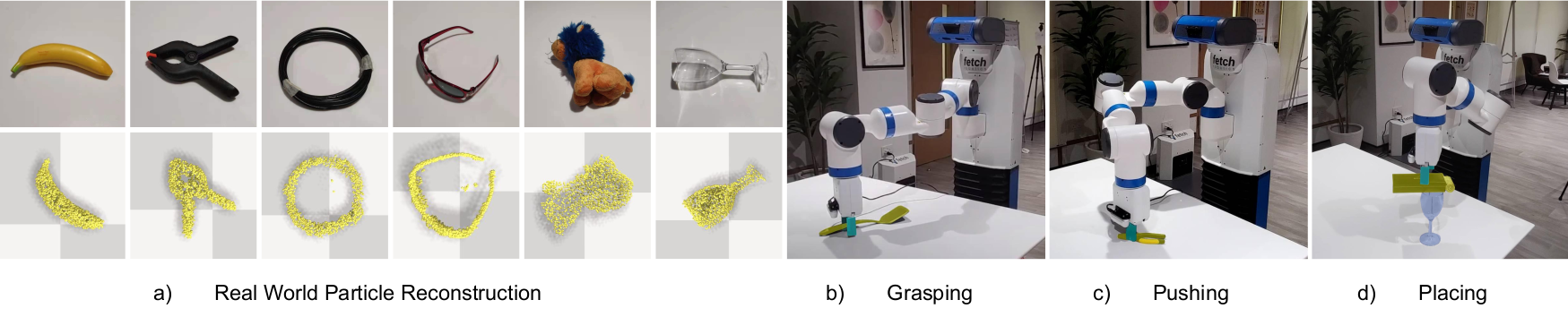
We present Particle-based Object Manipulation (Prompt), a new approach to robot manipulation of novel objects ab initio, without prior object models or pre-training on a large object data set. The key element of Prompt is a particle-based object representation, in which each particle represents a point in the object, the local geometric, physical, and other features of the point, and also its relation with other particles. Like the model-based analytic approaches to manipulation, the particle representation enables the robot to reason about the object’s geometry and dynamics in order to choose suitable manipulation actions. Like the data-driven approaches, the particle representation is learned online in real-time from visual sensor input, specifically, multi-view RGB images. The particle representation thus connects visual perception with robot control. Prompt combines the benefits of both model-based reasoning and data-driven learning.
DaxBench
S. Chen*, Y. Xu*, C. Yu*, L. Li, X. Ma, Z. Xu, D. Hsu. DaxBench: Benchmarking Deformable Object Manipulation with Differentiable Physics. Proceedings of The Eleventh International Conference on Learning Representations, ICLR 2023 (Oral). (*Co-first author)
 |  |  |
We extend the particle representation to deformable object manipulation with differentiable dynamics. Deformable object manipulation (DOM) is a long-standing challenge in robotics and has attracted significant interest recently. This paper presents DaXBench, a differentiable simulation framework for DOM. While existing work often focuses on a specific type of deformable objects, DaXBench supports fluid, rope, cloth …; it provides a general-purpose benchmark to evaluate widely different DOM methods, including planning, imitation learning, and reinforcement learning. DaXBench hence serves as a working bench to facilitate research on deformable object manipulation using particles.
DiPac
S. Chen, Y. Xu, C. Yu, L. Li, X. Ma, D. Hsu. Differentiable Particles for Deformable Object Manipulation.
PDF | Code

Furthermore, we utilize the concept of differentiable particles to manage a wide variety of deformable objects. The manipulation of such objects, including rope, cloth, or beans, presents a significant challenge due to their extensive degrees of freedom and complex non-linear dynamics. This paper introduces Differentiable Particles (DiPac), a novel algorithm designed for the manipulation of deformable objects. DiPac interprets a deformable object as a collection of particles and employs a differentiable particle dynamics simulator to rationalize robotic manipulation. DiPac uses a single representation – particles – for a diverse array of objects: scattered beans, rope, T-shirts, and so forth. The use of differentiable dynamics empowers DiPac to efficiently (i) estimate the dynamics parameters, effectively reducing the simulation-to-real gap, and (ii) select the best action by backpropagating the gradient along sampled trajectories.