Real-world robots often face a stochastic and partially observable environment. POMDP planning offers a principled approach to handle such uncertainties. However, POMDPs are also well-known for their computational complexity that grows exponentially with the problem scale and the planning horizon, namely, the “curse of dimension” and the “curse of history”. We aim to solve large-scale POMDP planning efficiently and scale-up to complex real-world tasks. The key to our solution includes: (i) one can leverage massive parallelization and powerful hardware to mitigate the “curse of dimension”, and (ii) one can integrate POMDP planning with learning to overcome the “curse of history”.
A perfect example of large-scale real-world tasks is Crowd-Driving: driving among an unregulated crowd of heterogeneous traffic agents. In crowd-driving, the robot vehicle must contend with a large-scale and highly interactive environment. Such complex environments require sophisticated long-term planning to achieve human-level performance. However, efficient planning is often prohibited due to real-time constraints. Shown below is a 3-mins talk introducing the crowd-driving problem and discussing how the problem can be modeled and solved using a combination of planning and learning. This video also summarizes the core technical approaches to be introduced in this post:
HyP-DESPOT
Panpan Cai, Yuanfu Luo, David Hsu, and Wee Sun Lee. HyP-DESPOT: A Hybrid Parallel Algorithm for Online Planning under Uncertainty. Int. J. Robotics Research, 40(2–3), 2021.
PDF | code
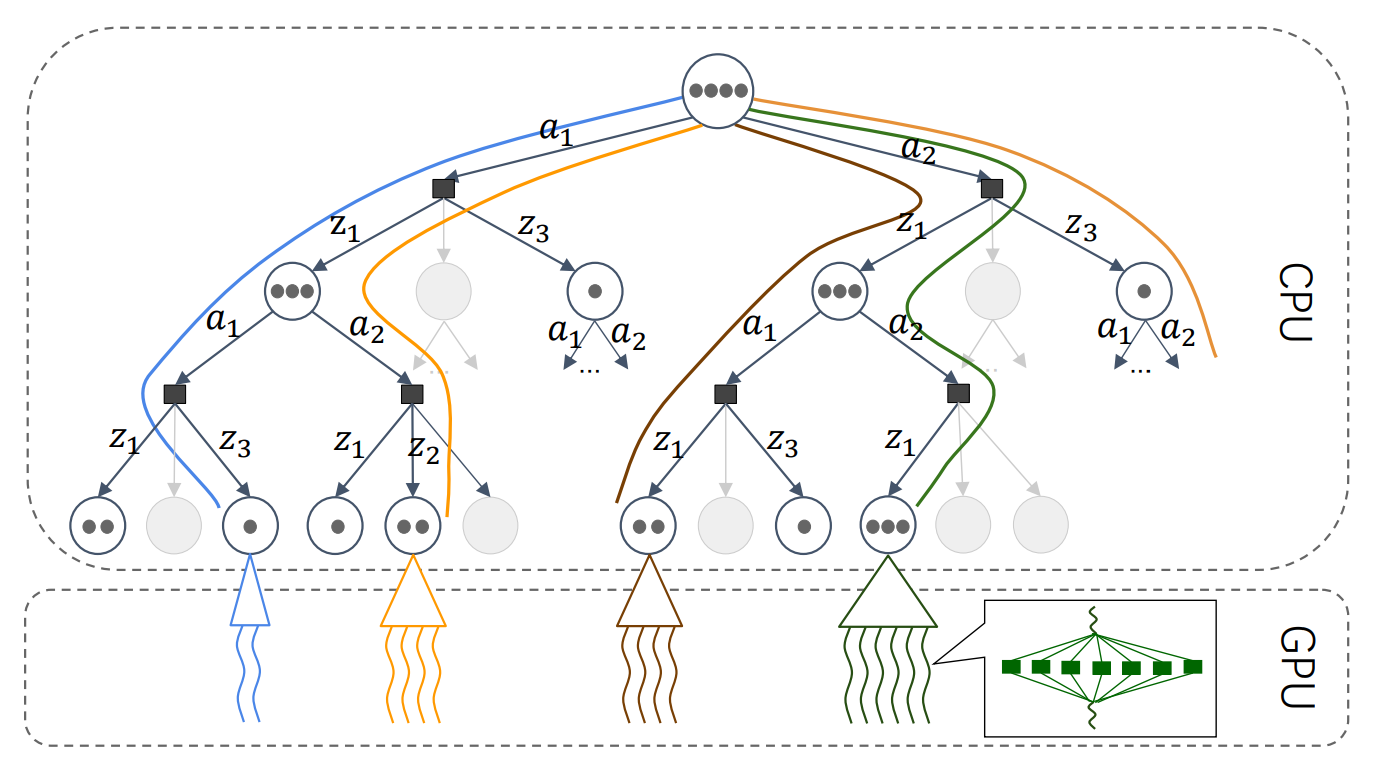
Hybrid Parallel DESPOT (HyP-DESPOT) is a massively parallel belief tree search algorithm that leverages both CPU and GPU parallelization in order to achieve real-time planning performance for complex tasks with large state, action, and observation spaces. In multi-core CPUs, HyP-DESPOT performs parallel DESPOT tree search by simultaneously traversing multiple independent paths; In the GPU, HyP-DESPOT performs parallel Monte Carlo simulations at the leaf nodes of the search tree. HyP-DESPOT provably converges in finite time under moderate conditions and guarantees near-optimality of the solution. In practice, HyP-DESPOT speeds up online planning by up to a factor of several hundred in several challenging robotic tasks.
LeTS-Drive
Panpan Cai, Yuanfu Luo, Aseem Saxena, David Hsu, and Wee Sun Lee. LeTS-Drive: Driving in a Crowd by Learning from Tree Search. In Proc. Robotics: Science & Systems, 2019.
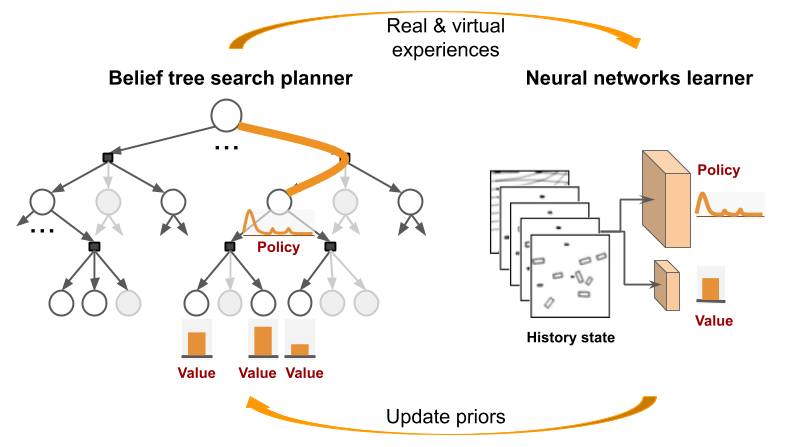
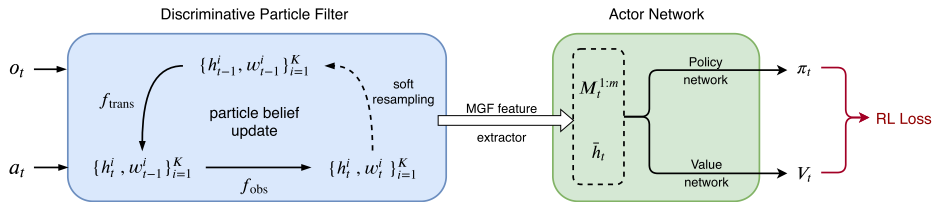
LeTS-Drive is a crowd-driving algorithm that integrates online POMDP planning with deep learning. The core idea is to constrain belief tree search to short-term futures and use learning for long-term futures. It consists of two phases. In the offline phase, we learn a policy and the corresponding value function by imitating the belief tree search expert. In the online phase, LeTS-Drive uses the learned policy and value function to inform and guide the online belief tree search. LeTS-Drive leverages the robustness of planning and the runtime efficiency of learning to enhance the performance of both. By integrating planning and learning, LeTS-Drive outperforms either planning or imitation learning alone and develops sophisticated crowd-driving skills.

LeTS-Drive-Auto
Panpan Cai, David Hsu, Think Locally, Learn Globally. to be uploaded to Arxiv.
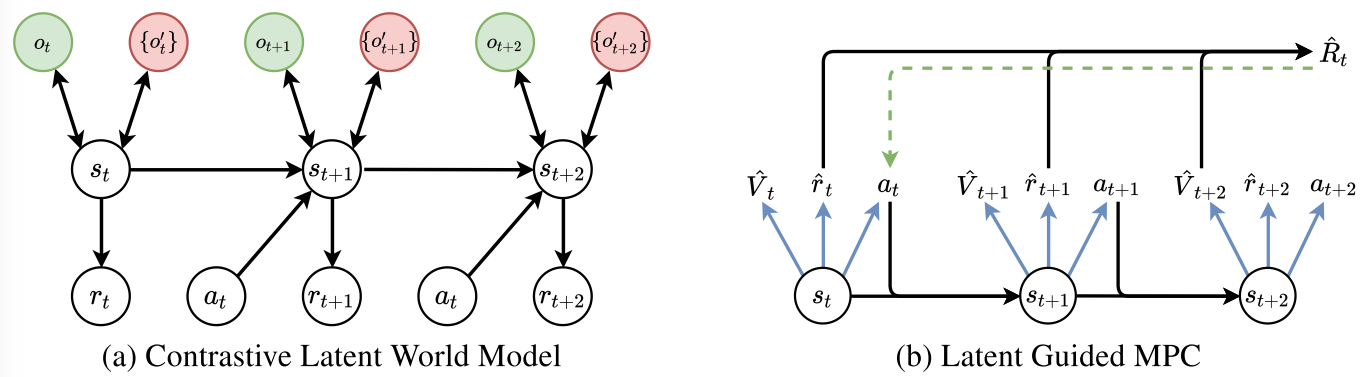
LeTS-Drive-Auto advances LeTS-Drive by integrating planning and learning in a close-loop. Similar to LeTS-Drive, it learns a policy network and a value network as representations of global priors. Differently, LeTS-Drive-Auto builds mutual communication between the planner and the learner by 1) guiding the online planner using learned global priors; 2) learning the global priors from data sent back from the guided planner. LeTS-Drive-Auto is a new reinforcement learning algorithm that the planner serves as the policy improvement operator and evolves together with the learner. By integrating planning and learning in a close-loop, LeTS-Drive-Auto achieves superior driving performance in crowded urban environments in simulation, outperforming either planning or learning alone, and largely exceeds the capability of open-loop integration (LeTS-Drive).
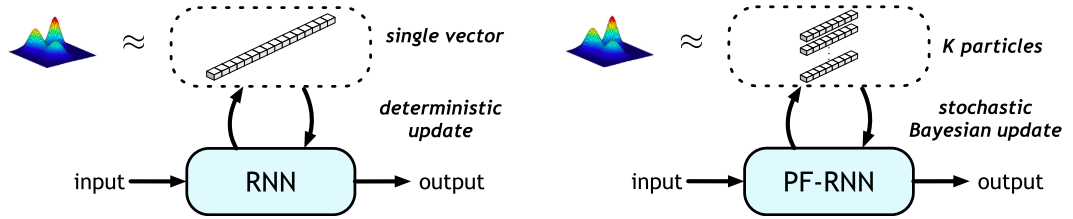



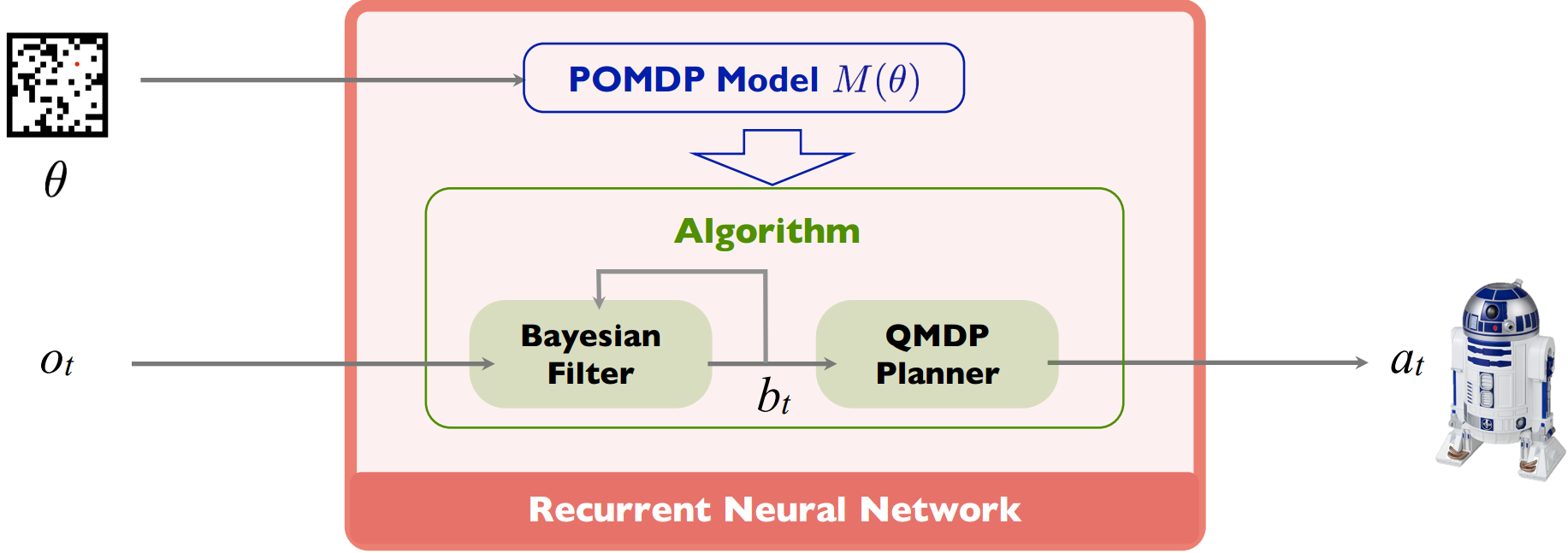
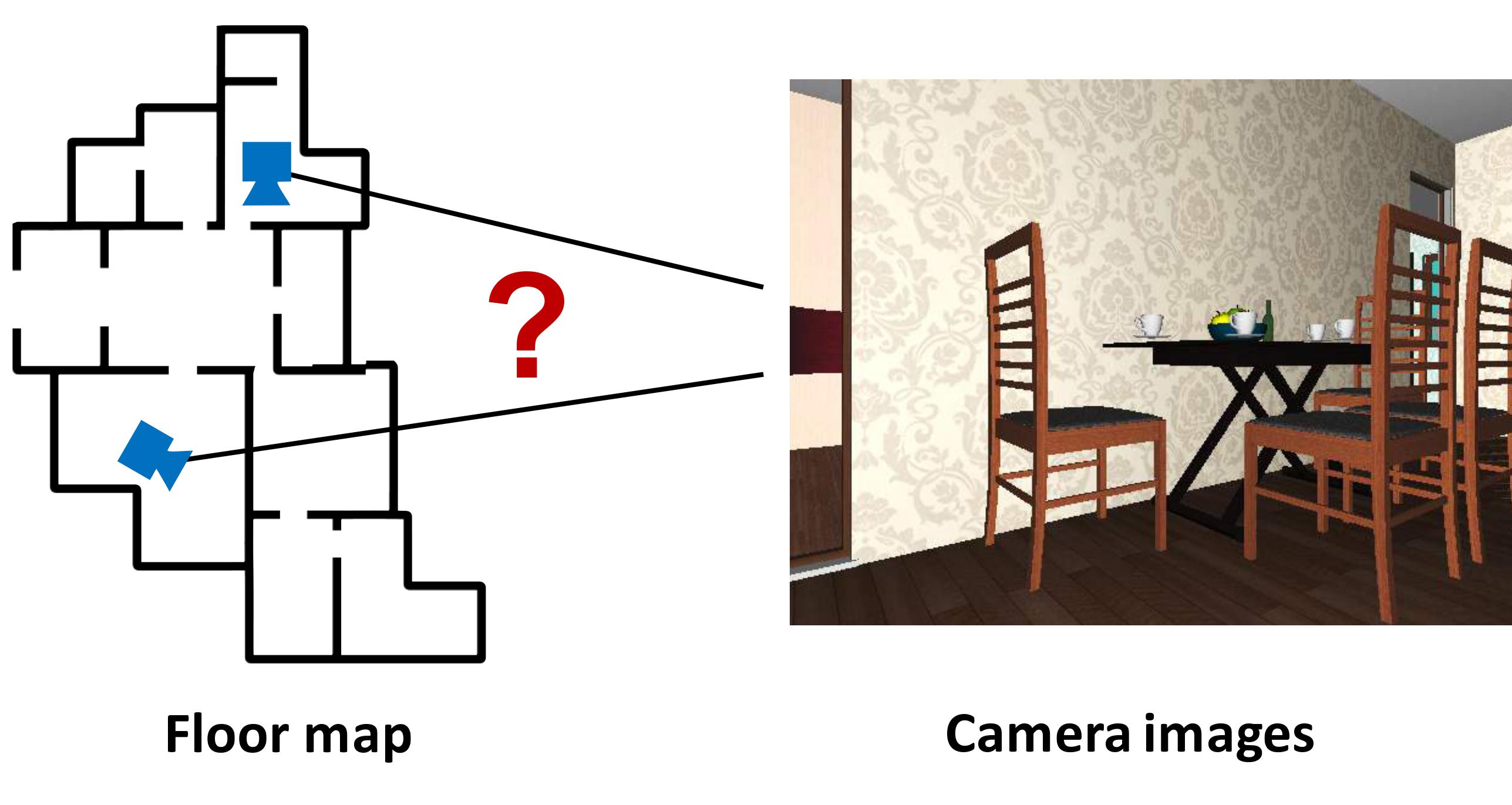
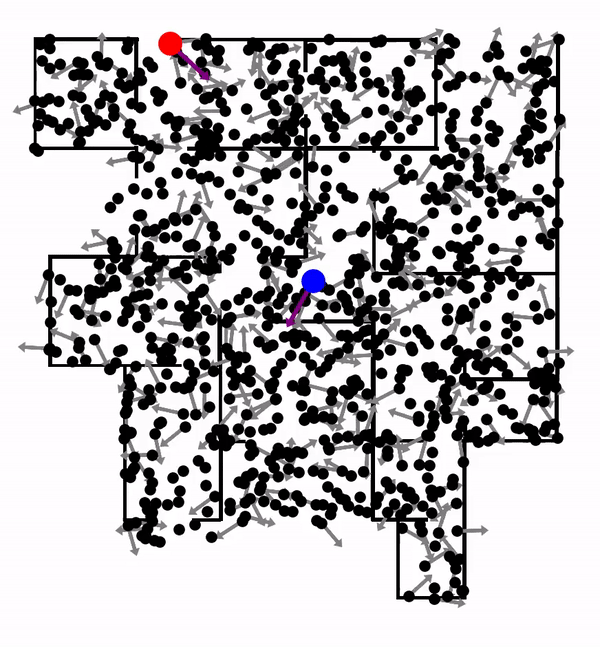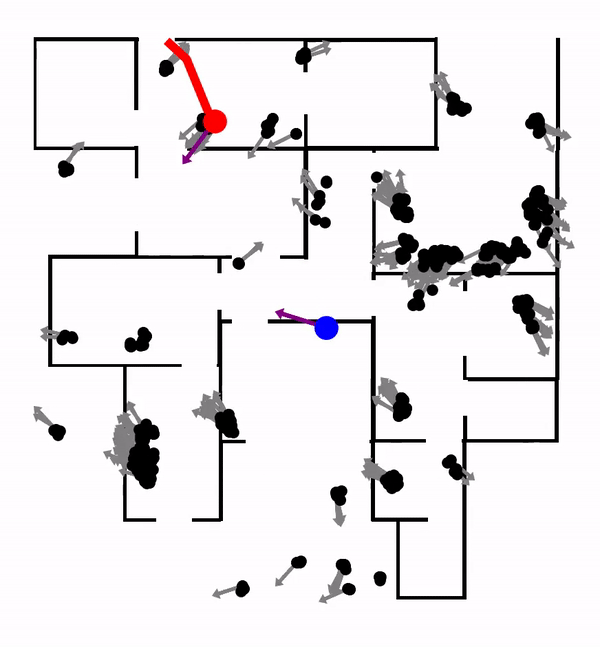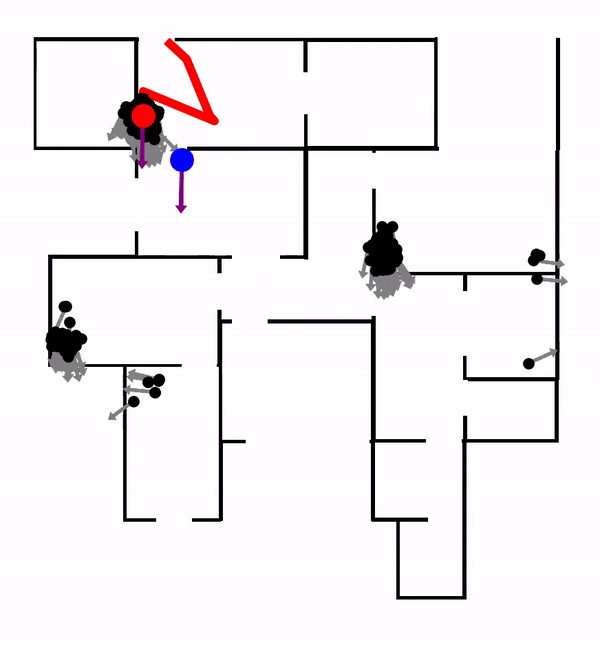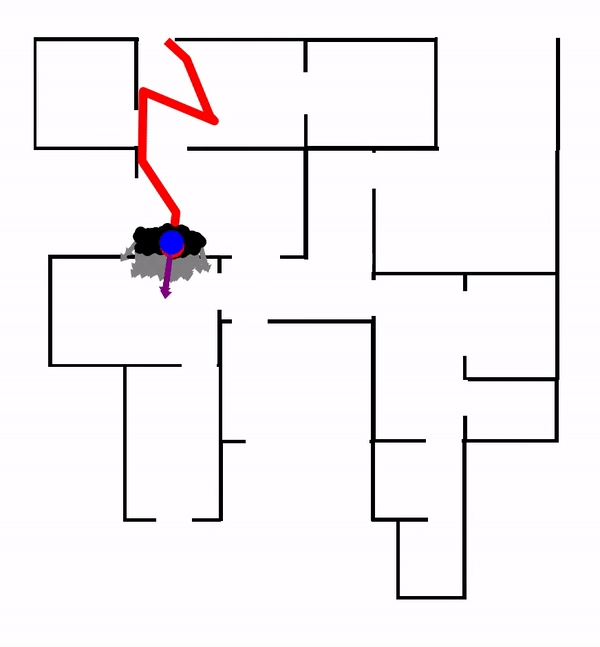
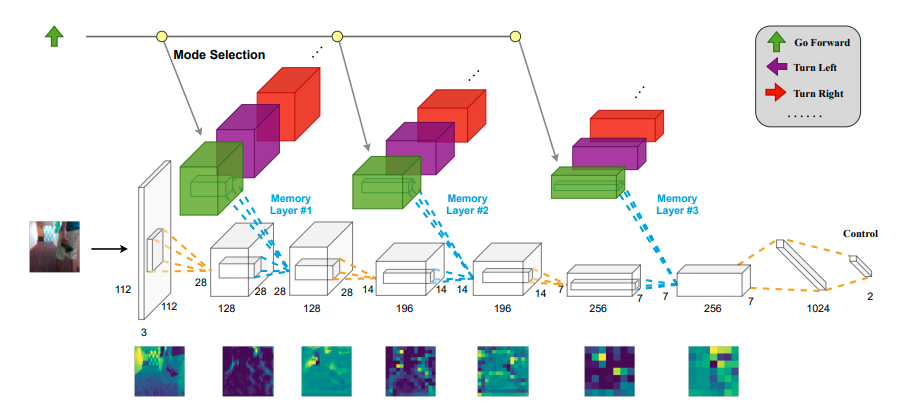
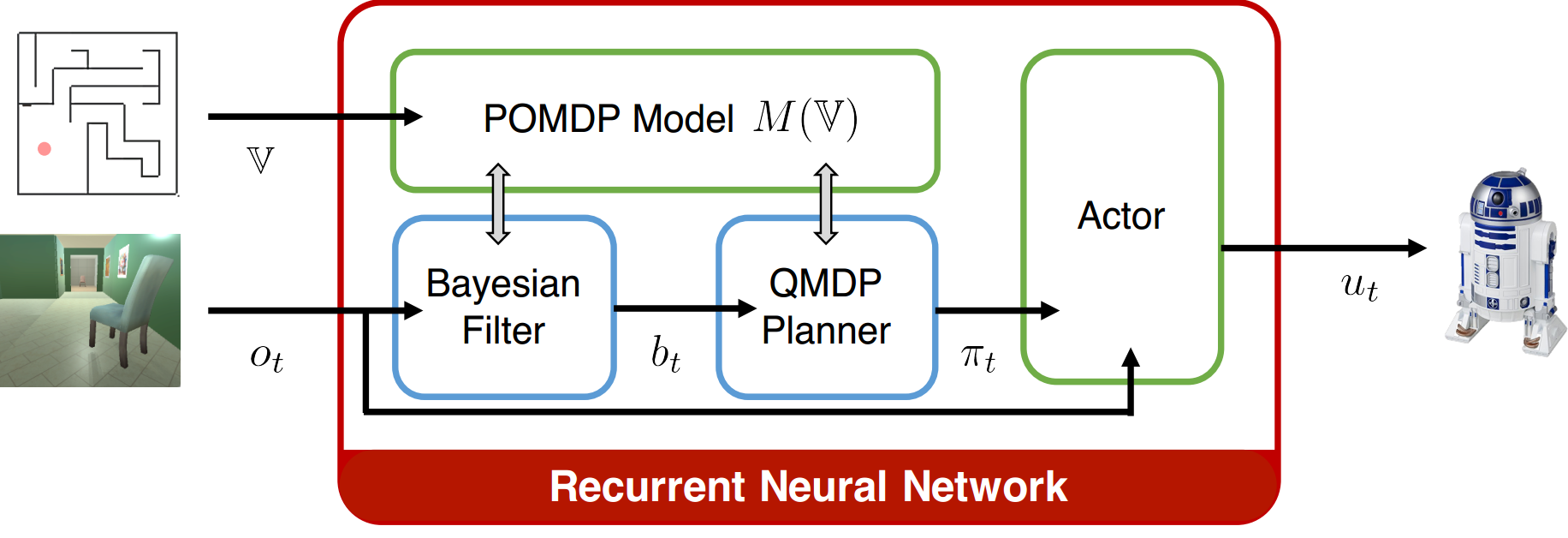 This work extends the QMDP-net, and encodes all components of a larger robotic system in a single neural network: state estimation, planning, and control. We apply the idea to a challenging partially observable navigation task: a robot must navigate to a goal in a previously unseen 3-D environment without knowing its initial location, and instead relying on a 2-D floor map and visual observations from an onboard camera.
This work extends the QMDP-net, and encodes all components of a larger robotic system in a single neural network: state estimation, planning, and control. We apply the idea to a challenging partially observable navigation task: a robot must navigate to a goal in a previously unseen 3-D environment without knowing its initial location, and instead relying on a 2-D floor map and visual observations from an onboard camera.